用python爬虫爬取lol皮肤。
这也用python网络爬虫爬取lol英雄皮肤,忘了是看哪个大神的博客(由于当时学了下就一直放在这儿,现在又才拿出来,再加上马上要考二级挺忙的。),代码基本上是没改,还望大神原谅。本人小白,没学过Python,只是去尝试体python爬虫的感觉和经验,正准备学python。忘大神勿喷。来一句:“人生苦短,我用python”。
先上一波图












个人感觉还是挺好的。下面我们就来学习一下怎样爬取?
所需要的函数库有json re(正则表达式库) requests和time是python自带的
其中只有requests需要通过cmd命令行安装,安装方法就是在python安装目录下用cmd命令行输入下面字符
pip Install requests
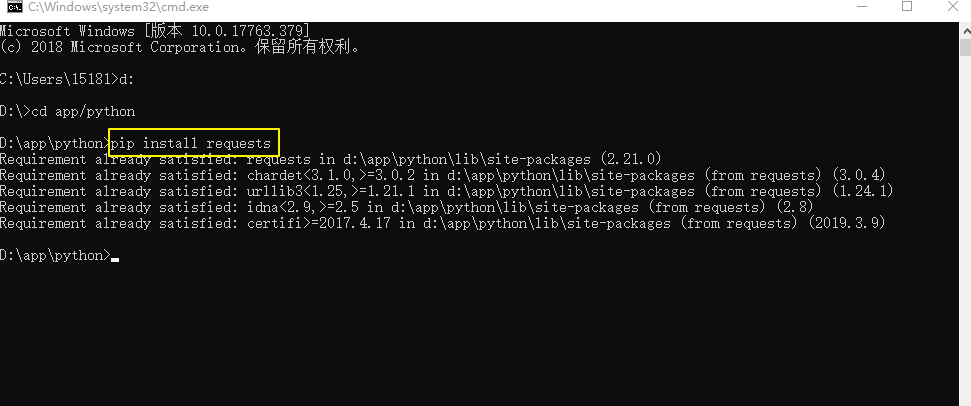
由于我已经安装过了,所以提示我已经安装了。
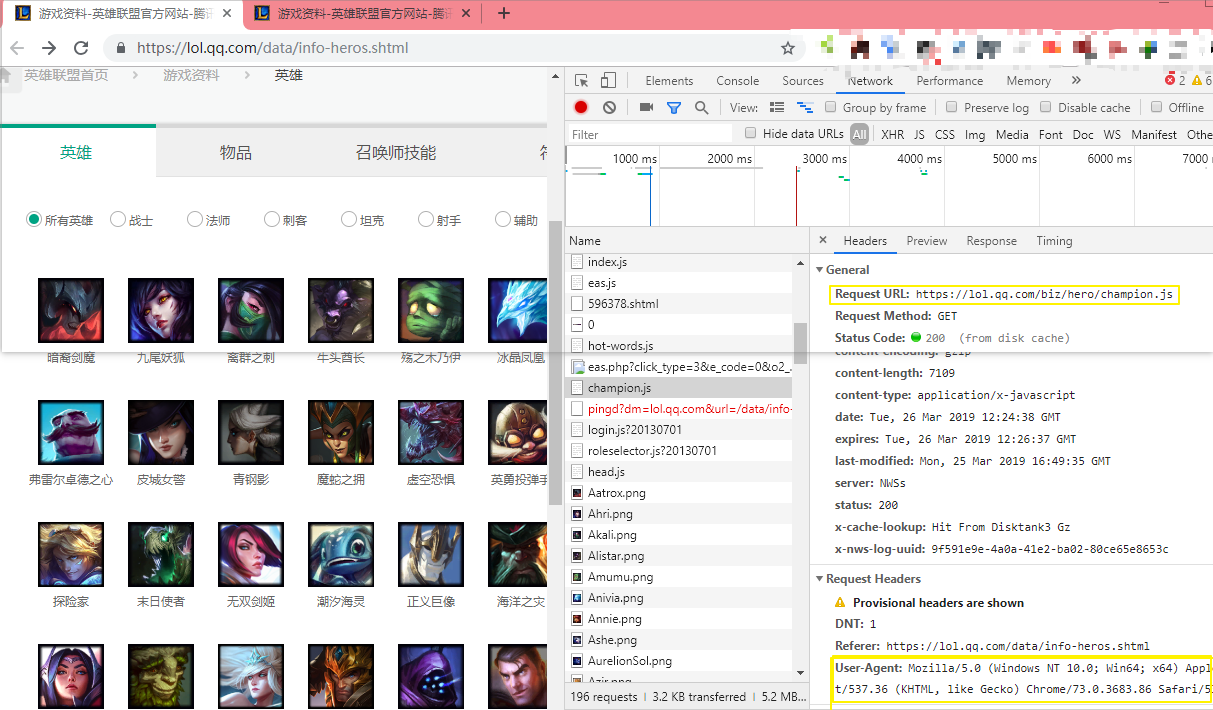
第一步是获取英雄id
ID的获取地址是从英雄联盟官网F12后在Network里找到champion.js,具体地址如下
http://lol.qq.com/biz/hero/champion.js
1 | import re |
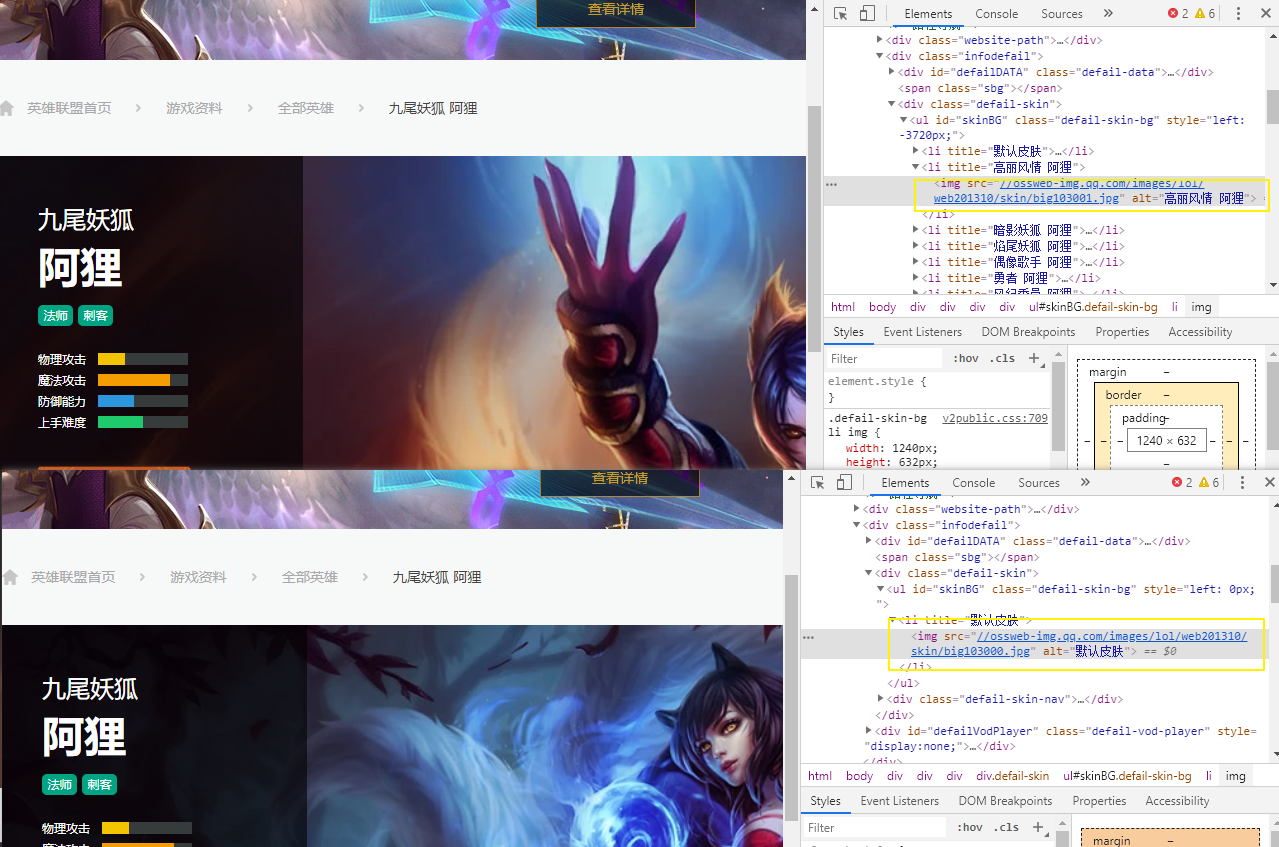
第二步就是拼接URL了,通过发现英雄皮肤url的取名方式,我们可以方向最后的数字是不同的。让后通过此方法来获取图片地址。
1 | for i in range(20): |
第三步是获取图片名称,path那行是放置图片的地址,注意结尾的\\不能丢。路径要设置成自己的。
1 | list_filepath = [] |
第四步就是下载图片了,注释掉time.sleep(1)后会加速爬取速度 但是可能被腾讯中断爬取。
1 | n = 0 |
下面是全部代码:
1 | import json |
以下是我的部分代码
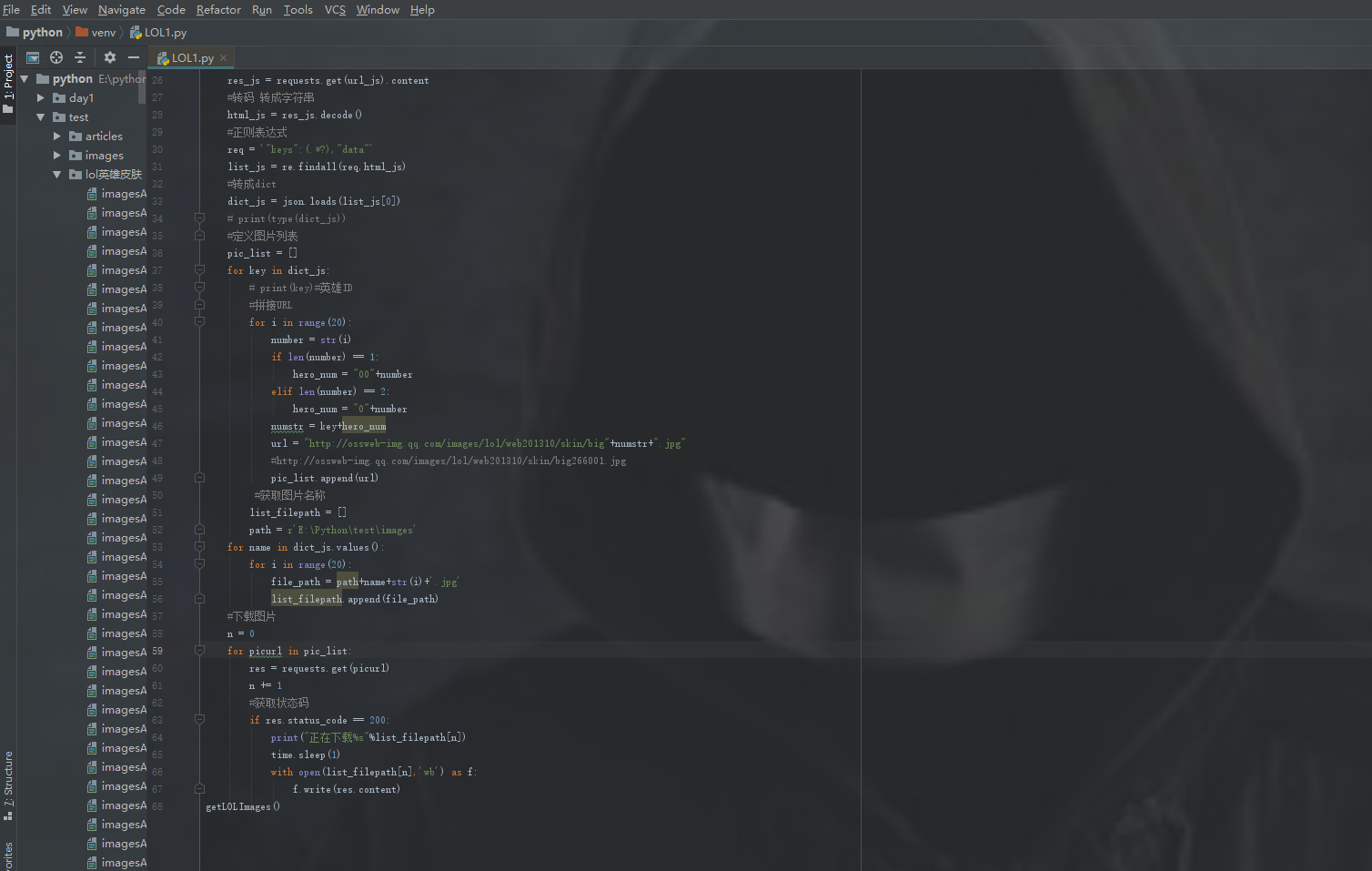
我对以上代码也是有点懵毕竟刚接触,如果大家有意要LOL皮肤的可以给在评论去找我。展示一下,我下了所有的哈哈。。。。。。。。

最后:大家学爬虫一定要遵守法律,切勿用作商用。
来自博主的忠告:博主提醒你,爬虫不规范,牢底坐穿,亲人两行泪!
